

Energy sector data intelligence platform
How we replaced
four disconnected
systems with one
unified platform for
energy grid engineering.
Despite having a highly skilled engineering team, PowerGrid Solution struggled with data fragmentation, manual reporting that consumed weeks, and automations that kept breaking. We built a modular AI platform that mirrors their existing workflow, replacing each manual step with an automated equivalent. No new concepts to learn.
Despite having a highly skilled engineering team, PowerGrid Solution struggled with data fragmentation, manual reporting that consumed weeks, and automations that kept breaking. We built a modular AI platform that mirrors their existing workflow, replacing each manual step with an automated equivalent. No new concepts to learn.
Four systems, zero interoperability
The engineering team was spending more time fighting their tools than doing engineering. Manual processes that should have been automated were consuming the majority of each project's timeline.
3 Weeks
Documentation time per project
4 Systems
Disconnected data sources
At Delivery
When errors were caught

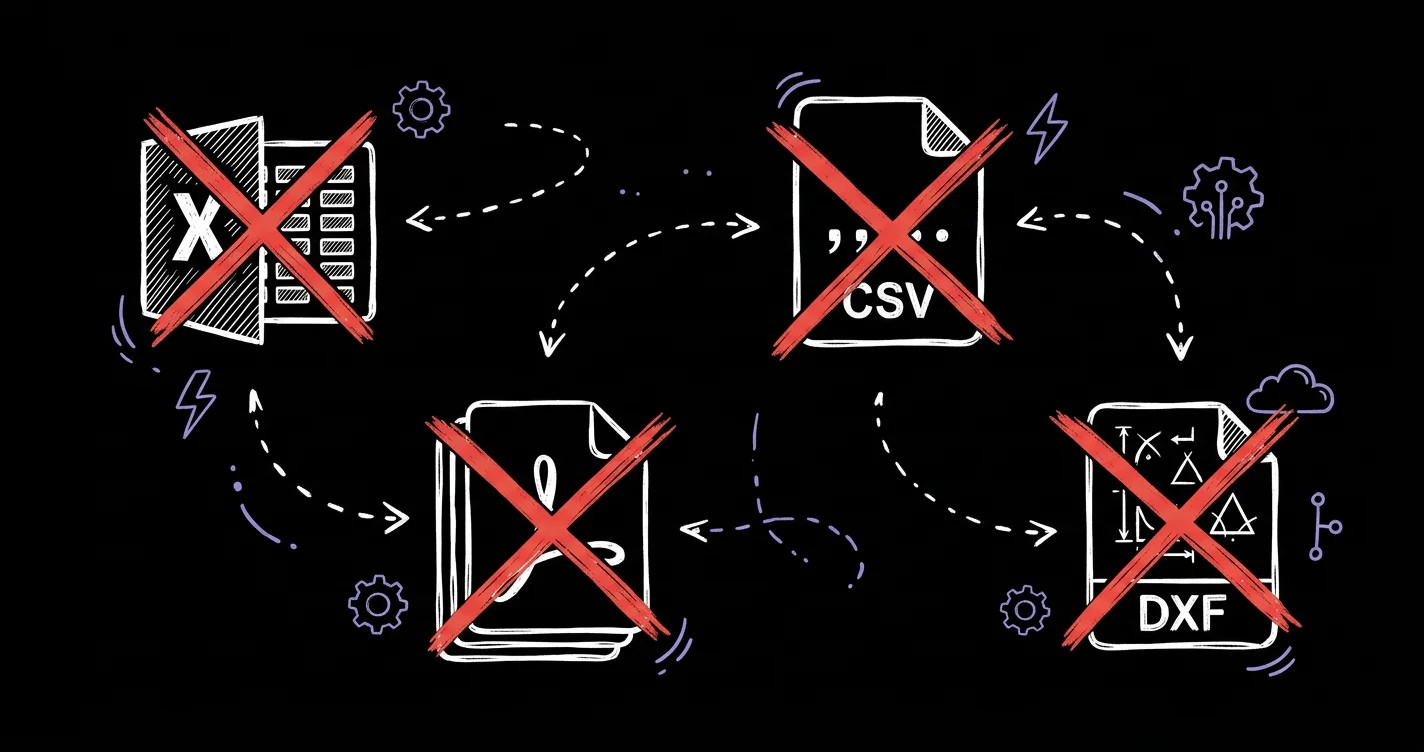
Data in four disconnected formats: Excel workbooks (5 sheets, ~35,000 rows each), CSV exports, PDF documents, and DXF.
Manual reporting consumed weeks: one documentation set required pulling data from multiple sources, cross-checking manually, assembling in Word.
Minor formatting changes broke existing formula errors surfaced only at delivery. No automated validation. Inconsistencies caught during client review, causing rework and deadline pressure.
Previous automations failed: internal Excel macros were fragile and broke whenever input formats changed slightly.
“The engineering team was spending more time fighting their tools than doing engineering. Manual processes that should have been automated were consuming the majority of each project's timeline.”
Their expectation
PowerGrid needed a single platform that could ingest all four data formats, automatically reconcile and deduplicate entries, generate compliant documentation, and eliminate the manual cross-referencing that consumed three weeks per project.
They needed it to work exactly the way their engineers already think.
Solutions
We designed a modular AI platform that mirrors PowerGrid's existing workflow, replacing each manual step with an automated equivalent. No new concepts to learn.
Platform Architecture
The platform consists of five integrated modules built on Next.js 16, React 19, and FastAPI. S1 handles centralized data management with a 9-step guided wizard. AI entity resolution processes 44M+ comparisons using fuzzy matching to detect duplicates and standardize data for Delgaz export format.
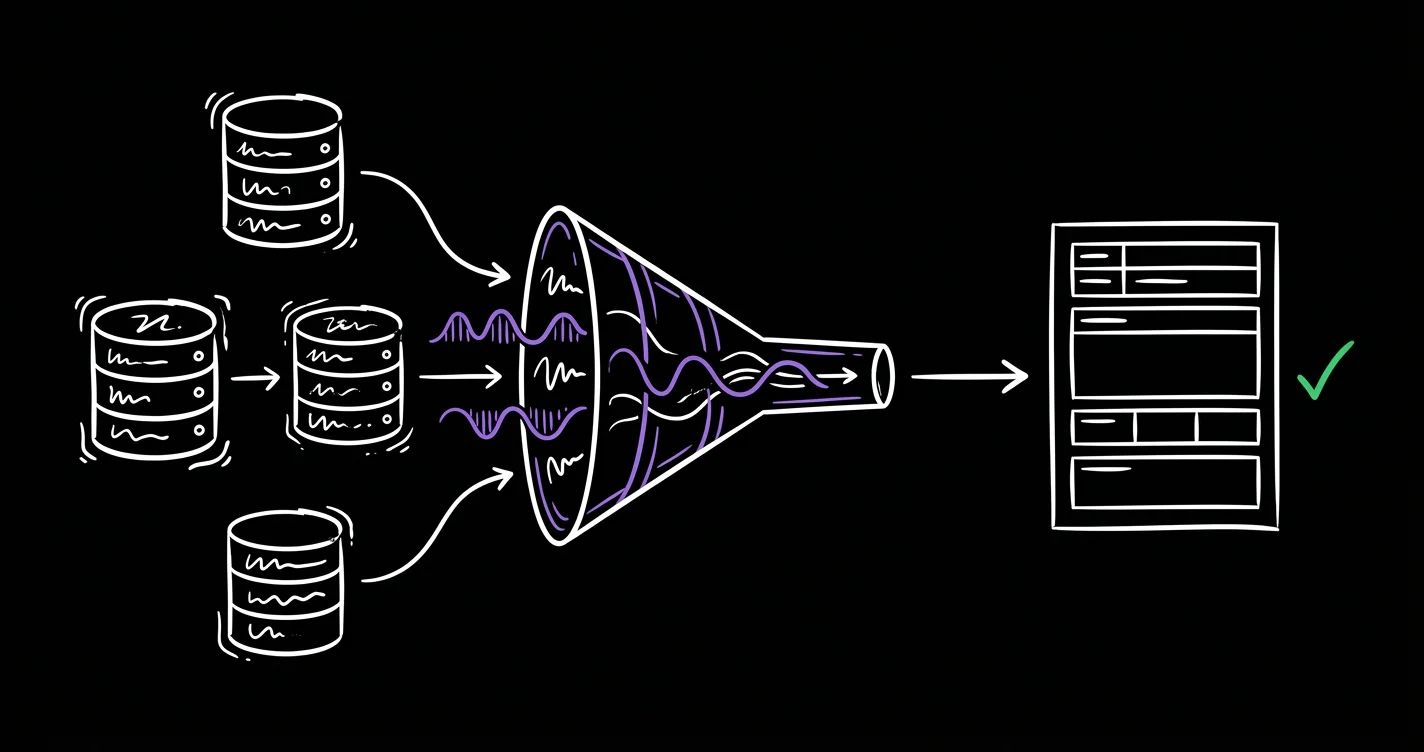
Ingest
Import all four source formats (Excel, CSV, PDF, DXF) into a unified internal schema.
Compare
44M+ pairwise comparisons using multiple hashing algorithms optimized for energy-sector naming patterns.
Score
Every candidate match receives a confidence score. High-confidence clusters are surfaced first.
Review
Engineer approves or rejects each proposed match. No automatic merging without human sign-off.
Persist
Confirmed matches enter the alias table permanently. One authoritative record per entity across all sources.
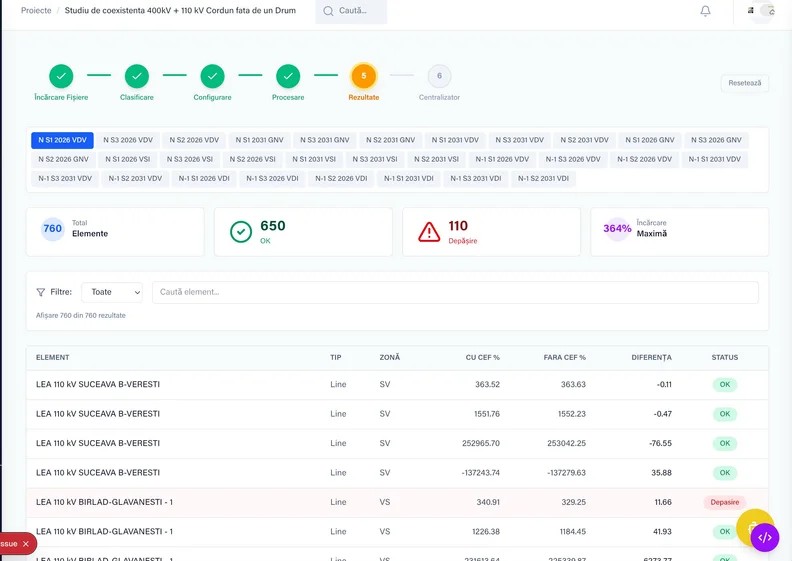
Automated Analysis
The S2 module automates technical analysis by parsing Neplan Power System exports. It compares N vs N-1 scenarios, flags threshold violations, and generates reports in both PDF and XLSX.
What previously required days of manual comparison is now completed in minutes.
What used to be two days of work is now a button click
Import Neplan export, any project, any format version
Normal operation vs. N-1 fault analysis calculated automatically
Threshold breaches flagged with configurable engineering limits
Structured report generated, the engineer reviews output, not raw data
Intelligent Documentation
Auto-generates technical memorandums from structured project data. An AI verification layer cross-checks generated text against source drawings and S1/S2 data before any document reaches the client.
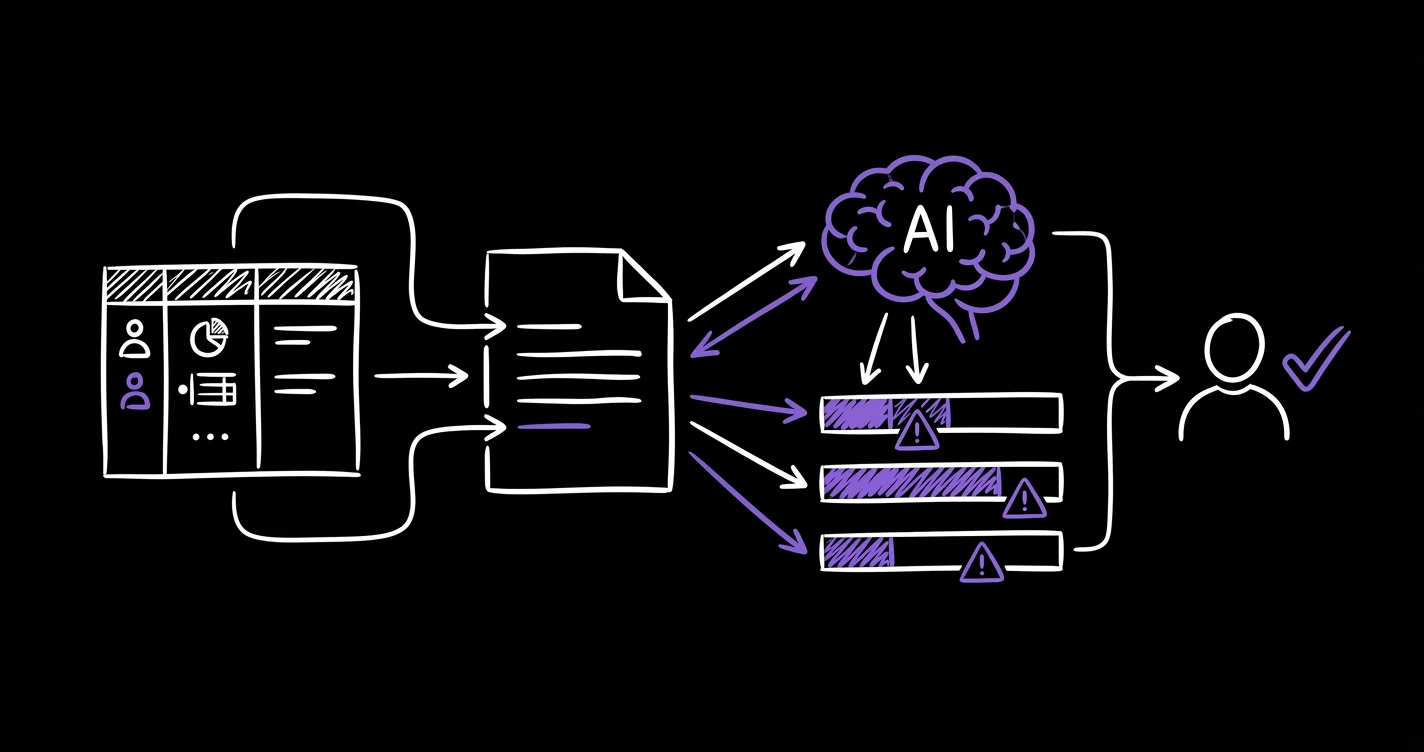
“If the text says 95kV and the data says 110kV, the system flags it before it leaves the building.”
Before this, contradictions were caught by the client after delivery. The cost of that — revisions, delays, damage to credibility — was real. Now they get caught before anyone signs off.
Zero undetected contradictions between report text and underlying data.
One platform, five capabilities
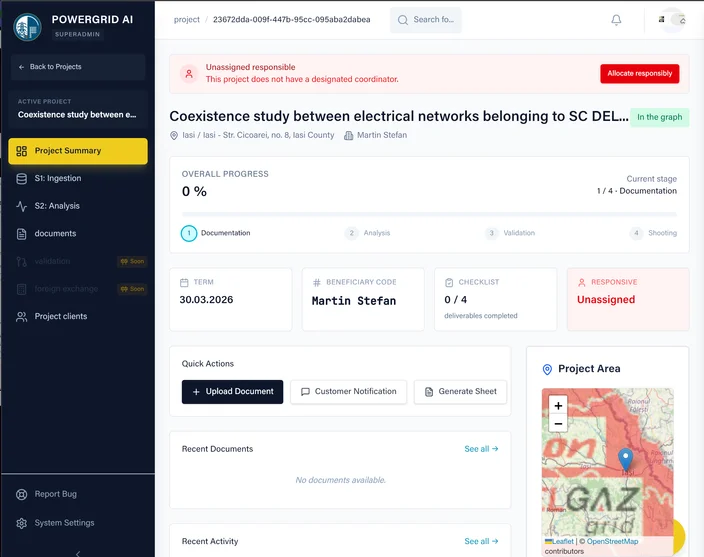
Project Management
Centralized project tracking with progress monitoring, task assignment, and deadline management across all engineering projects.
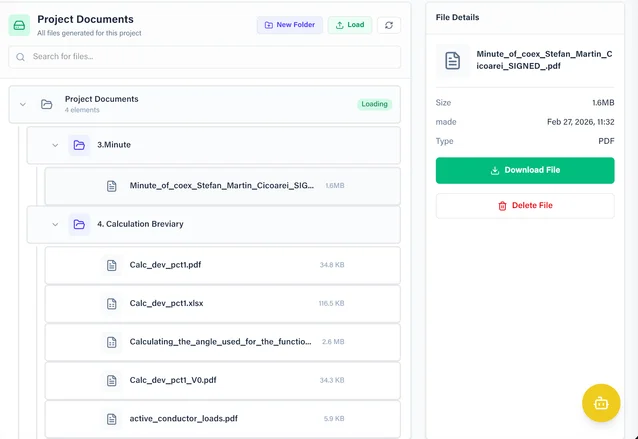
Project Documentation
Automated document generation, file management, and version control for all technical deliverables.
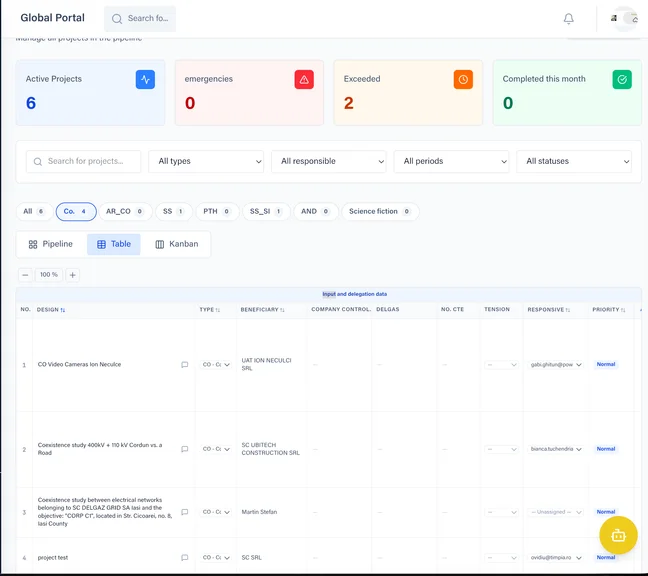
CRM / Budgeting
Client relationship management with pipeline tracking, budget monitoring, and project financials in one view.

Tasks & Communication
Built-in task assignment with email notifications. Engineers get mentioned and notified directly from the platform.
AI Analysis
Automated technical analysis with N vs N-1 scenario comparison, threshold violation detection, and structured reporting.
Enterprise-Grade Security
Multi-factor authentication (TOTP), role-based access control, and full audit trails. Every action is logged with user, timestamp, and IP. Deployed on EU infrastructure with GDPR compliance built in from day one.
Results
The platform delivered measurable impact from day one. Documentation time dropped from three weeks to five minutes. Four disconnected systems became one unified platform.

40%
Cost Reduction
5 min
Technical Documentation Time
x7.5
ROI
The impact went beyond speed. With automated verification, errors that previously surfaced only during client review are now caught before export. The engineering team spends their time on actual engineering instead of fighting spreadsheets.
Zero training sessions were needed for onboarding. The system was designed to mirror the engineers' existing mental model. The team went live on EU infrastructure with MFA, role-based access, and full audit trails from day one.
Deployment Timeline
From first contact to production in 10 weeks. The lead came through a referral from an existing Timpia client. Within 48 hours we delivered a structured proposal. Within a week we were on a screen share watching their engineers work.
The iterative 2-week sprint cycle meant working software was delivered every two weeks with real data. By week 10, all five modules were live, processing the full 44M+ data point volume, with 100% team adoption without a single formal training session.


The Architecture
Built for enterprise, deployed on EU infrastructure. Every component was chosen for a reason.
RapidFuzz and TF-IDF handle 44 million entity comparisons without breaking a sweat. OpenAI GPT-4 generates documentation that passes engineer review on first draft. Dramatiq workers process 5-sheet workbooks with 35,000 rows each in under 90 seconds. All data stays on EU-hosted Supabase with MFA, role-based access, and full audit trails from day one.
Client Feedback
This project proved that AI doesn't need to replace engineers. It needs to think like them. By embedding ourselves in PowerGrid's daily workflow before writing a single line of code, we built a platform that achieved 95% time reduction with zero training sessions.
I'll be honest. When Ovidiu and his team first came to us, I told them: “We've tried this before. Macros break, vendors don't understand our work.” But they did something no one else had done.
They sat with us for an entire week. Watched how Ionut opens his spreadsheets at 7am. How Maria cross-checks Neplan exports by hand. How I spend every Friday reformatting the same tables into Word documents. They didn't try to change us. They built something that thinks the way we think.
The first time I uploaded a 35,000-row workbook and saw it deduplicated in seconds, something that used to take me three days, I called Ovidiu at 10pm to tell him. My team now finishes in one afternoon what used to take three weeks. No one needed training. They just sat down and started using it.
44 million comparisons. Zero errors at delivery. The system didn't just replace our tools. It gave us back our weekends.
Florin Baiceanu
Lead Engineer & Partner, PowerGrid Solution S.R.L., Iasi
What this demonstrates
Data-first thinking
We solved the identity problem before touching any automation. Entity resolution was the foundation, and every other capability in the platform sits on top of it.
Process automation at scale
Over 44 million comparisons, five automation pipelines, and grid analysis that used to take two days now runs on demand, all on commodity infrastructure.
Human-in-the-loop by design
Every merge and every document requires explicit sign-off. The platform proposes, the engineer decides. Automation that doesn't strip away accountability.
Zero training adoption
By embedding ourselves in the team's daily workflow before writing code, we built a platform that mirrors how engineers already think. 100% adoption without a single training session.
EU-native infrastructure
Built for regulated industries from day one. Data stays within the EU by architecture, not just by policy. MFA, RBAC, full audit trails.
